يكي
از اساسيترين كارهايي كه بعد از پيادهسازي يك بانك اطلاعاتي و در حين
استفاده كاربران از آن بايد صورت گيرد، نظارت دقيق بر رفتار سيستم و بررسي
واكنشهايي است كه آن بانك اطلاعاتي در شرايط خاص و ضمن استفادههاي متنوع
كاربران مختلف از خود نشان ميدهد. بنابراين اين نظارت دايمي بايد طبق
اصول خاص و يك برنامه منظم و با استفاده از امكاناتي كه بانك اطلاعاتي در
اختيار مديريت سيستم قرار ميدهد انجام گيرد تا از بروز مشكلات احتمالي
جلوگيري به عمل آيد. اين مشكلات به طور كلي به سه دسته عمده كُند شدن
سرعت جستجو در سيستم (Query performance problem) ،كم شدن تعداد فرايندهاي
قابل اجرا در واحد زمان (Transactions Throughput problem) ،كاهش كارايي
سيستم در اثر افزايش كاربران و تداخل كارهاي آنها در يكديگر ( Concurrent
users problem) تقسيم ميشود. براي اين منظور در SQLerver ابزارهاي خاصي
براي مانيتورينگ سيستم درنظر گرفته شده تا مدير سيستم بتواند به موقع نقاط
ضعف سيستم (از لحاظ نرمافزاري يا سختافزاري) را شناسايي كرده و قبل از
اينكه سيستم را دچار بحران نمايد يا اينكه كار به گلهمند شدن كاربران
بيانجامد با مشورت طراحان، برنامهنويسان و مسؤولين شبكه راهحل مناسبي
براي آن مشكل پيدا كند. در صورت كشف مشكل مذكور، ايجاد تغييراتي در روابط
منطقي يا فيزيكي جداول بانك اطلاعاتي توسط طراحان بانك، بهينهسازي كدهاي
برنامهنويسي شده و رفع نقاط ضعف آن توسط برنامهنويسان و ارتقاي
سختافزار شبكه و سرور بانك اطلاعاتي توسط مسؤولين شبكه ميتواند راهگشاي
بسياري از اين نوع معضلات به حساب آيد. در SQL Server يك ابزار مناسب براي
مانيتورينگ يك بانك اطلاعاتي وجود دارد كه در اينجا به معرفي آن
ميپردازيم.
SQL Server Profiler
اين
ابزار در واقع برنامهاي است كه قادر به اشكالزدايي دستورات SQL ميباشد.
هر نوع دستور SQL كه به تنهايي يا از داخل يك برنامه يا از طرف يك روال
ذخيره شده (Stroed Procedvre) و يا هر جاي ديگر اجرا شود توسط اين برنامه
شناسايي و ثبت ميشود. سپس برنامه مذكور عمل تجزيه وتحليل خود را بر روي
اين دستور SQL انجام داده و نتايج آن را به مدير سيستم نمايش ميدهد.
نحوه كار برنامه
برنامه
پروفايلر ليستي از رخدادهايي را كه قادر به تعقيب آنها است در اختيار
كاربر قرار ميدهد. اين رخدادها پس از انتخاب كاربر در درون يك صف
(Queue) قرار گرفته و هرگاه يكي از رخدادها به وقوع بپيوندد، پروفايلر شرح
كاملي از جزييات آن را در يك فايل جهت گزارشي به مدير سيستم، ثبت ميكند.
اين عمليات تعقيب كه در پروفايلر به آنTrace گفته ميشود كاملاً توسط
كاربر قابل تنظيم است.
رخدادهاي قابل تعقيب توسط پروفايلر به انواع
مختلفي تقسيمبندي ميشوند كه در قسمت Events از منويWewTrace يعني
زمانيكه كاربر قصد تعريف يك تعقيب جديد را دارد، مشاهده ميشوند.
1- Cursors
اين
مجموعه رخدادهاي مربوط به اتفاقاتي است كه باعث ايجاد شدن، مورد استفاده
قرار گرفتن و حذف شدن يك دسته ركوردهاي اطلاعاتي از يك يا چند جدول
ميشود. همانطور كه ميدانيد در SQL Server ميتوان با استفاده از دستور
SELECT تعدادي از جداول بانك اطلاعاتي را با هم لينك كرده و مجموعه
ركوردهاي اطلاعاتي مربوطه را در يك گروه به نام كرسر قرار داد (همان چيزي
كه در زبانهاي برنامهنويسي مثل ويژوال بيسيك به آن Recordset گفته
ميشود) هر عملي كه باعث ايجاد شدن يا هر نوع عمليات ديگر بر روي يك كرسر
شود ميتواند مورد تعقيب پروفايلر قرار گرفته و ثبت شود.
2- Data Base
اين
مجموعه از رخدادها مربوط به فايلهاي دادهاي يك بانك اطلاعاتي است. هر
تغييري كه در ساير فايلهاي دادهاي و فايلهاي لاگ يك بانك ايجاد شود در
اين مجموعه قرار ميگيرد.
3- Errors and Warning
مقام
پيامهاي خطا و هشدار كه در زمان اجراي دستورات SQL يا در زمان كامپايل و
اجراي SPها و يا Triggerها به كاربر داده ميشود و همچنين خطاهاي مربوط به
OLE DB در اين گروه قرار ميگيرد.
4- Locks
اين
گروه از رخدادها، بيشتر زماني مورد استفاده قرار ميگيرد كه يك برنامه
كاربردي در قفل كردن و آزاد كردن ركوردهاي جداول بانك اطلاعاتي دچار ضعف و
اشتباه ميشود.
همانطور كه ميدانيد بسياري از برنامههاي كاربردي
در مقاطع زماني خاص اقدام به قفل كردن يك يا چند جدول اطلاعاتي ميكنند كه
اين كار و همچنين آزاد كردن آن جداول بايد با حساسيت و دقت خاصي انجام شود
تا در كار بقيه كاربران اخلال ايجاد نكند اما متأسفانه بسياري از اين نوع
برنامهها خصوصاً برنامههايي كه قدمت چنداني ندارند اغلب از اين لحاظ
دچار بيدقتي و ضعف زيادي هستند.
5- Scans
هر
عملي كه در حافظه اصلي تخصيص داده شده به SQL server قابل دستيابي باشد
در اين دسته قرار ميگيرد. بهخصوص عمليات مربوط به Cache كه در داخل
موتور بانك اطلاعاتي انجام ميشود جزو اين دسته محسوب ميشوند.
6- Stored procedveres
شامل
كليه وقايعي كه ممكن است براي يك روال رخ دهد ميباشد. كامپايل، فراخواني،
شروع اجرا، وضعيت در حال اجرا، پايان اجرا، همگي از جمله رخدادهاي قابل
وقوع در اين دسته ميباشند.
7- TSQL
اين
نوع رخدادها شامل كليه وقايعي است كه باعث اجراي هر يك از دستورات زبان
TSQL به صورت تكي يا دستهاي (Batch) ميشود. دستورات SELECT ،Insert
،UpdATE ، DELETE و ... هر كدام آغاز و پاياني مشخص با نتايج معين در يك
بانك اطلاعاتي دارند كه ميتوانند به وسيله اين نوع رخداد مورد بررسي قرار
گيرند.
8- Transaction
 |
|
شكل 1 |
در اين دسته، كليه وقايع مربوط به فرآيند از جمله شروع (BEGIN) تأييد
(Commit) و
بازگشت (Roll Back) قرار ميگيرند. هر فرآيند شامل چند دستور SQL ميباشد
كه يا بايد همگي بدون اشكال اجرا شوند و يا اينكه هيچكدام اجرا نگردند.
اهميت
فرآيند و استفاده مناسب از آنها در يك بانك اطلاعاتي و برنامه كاربردي
مربوط به آن جاي هيچگونه ترديدي را براي وجود ابزاري جهت ثبت و
مانيتورينگ وقايع باقي نميگذارد. لذا اين دسته از رخدادها همانند
رخدادهاي SQL يكي از پركاربردترين رخدادها قلمداد ميشوند.
9- Session
اين
دسته از وقايع شامل كليه رخدادهاي مربوط به اتصال كاربران به بانك
اطلاعاتي (login) و خروج از آن (logout) يا قطع اتصال در اثر بروز هر
عاملي (Disconnect) ميباشد و براي كنترل و رفع ايراد ورود و خروج كاربران
به سيستم مورد استفاده قرار ميگيرد.
اجراي آزمايشي يك Trace
 |
|
شكل 2 |
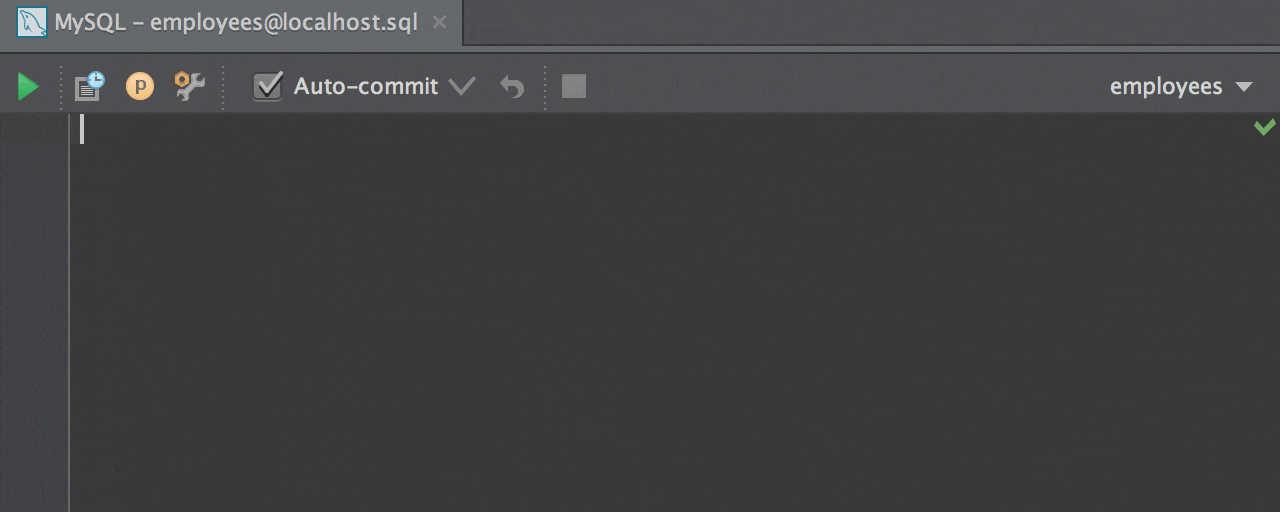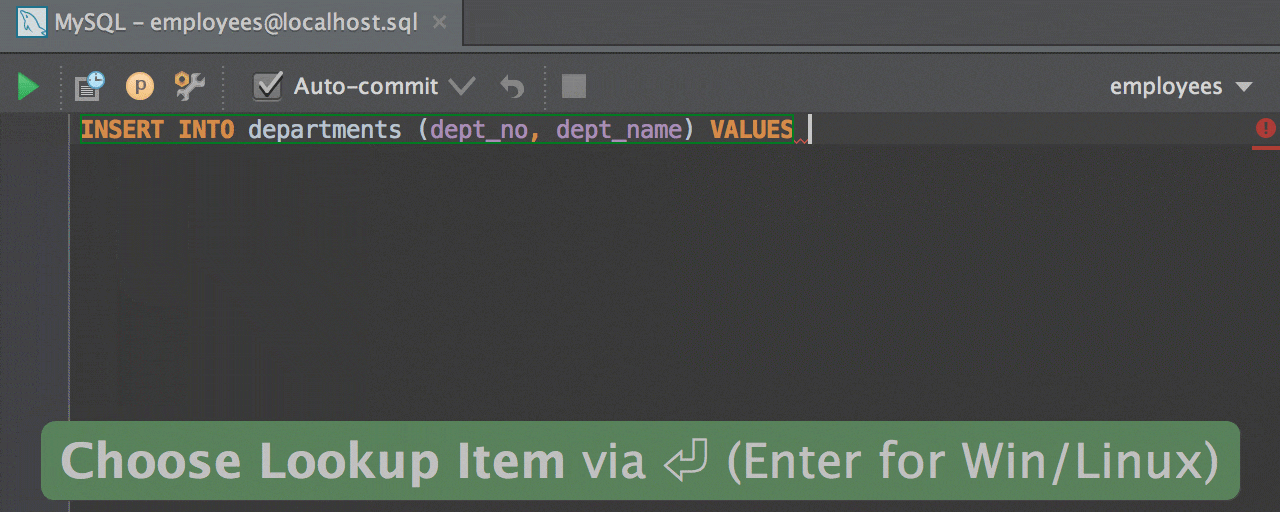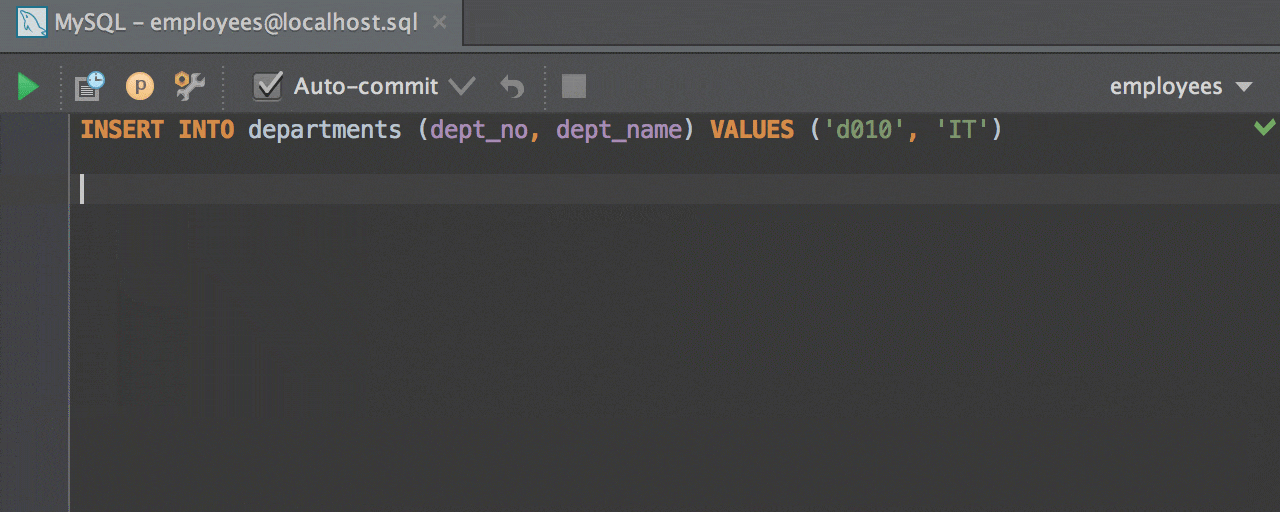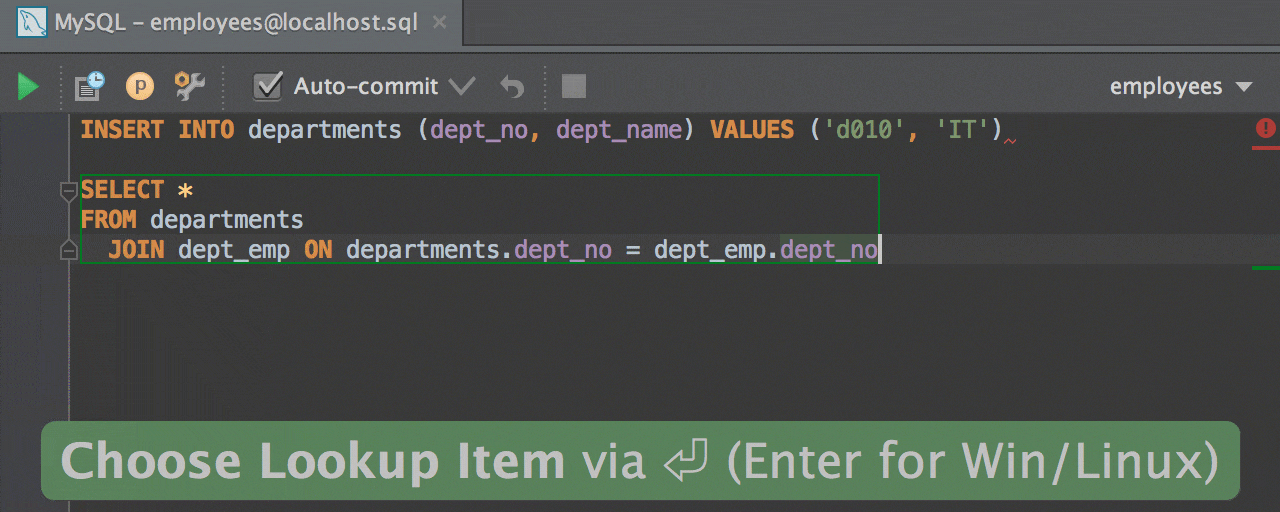
براي شروع، ميخواهيم يك
تعقيب آزمايشي براي ثبت برخي رخدادهاي قابل وقوع در سيستم با استفاده از
پروفايلر بسازيم. براي اينكار برنامه Profiler را اجرا كرده و منوي New
Trace را كليك ميكنيم تا ليستي از وقايع قابل ثبت كه آنها را در قسمت
قبل شرح داديم ظاهر شود. در قسمت General كافي است يك نام براي Trace
موردنظر انتخاب كرده و سپس يك مسير براي درج فايل حاوي لاگ رخدادهاي
مذكور، به پروفايلر معرفي كنيم. لازم به ذكر است كه پروفايلر قادر است به
جاي يك فايل، لاگهاي توليد شده را در يكي از جداول همان بانك اطلاعاتي
ذخيره كند. همچنين اگر مايل باشيد كه هيچ لاگي براي شما ثبت نشود،
پروفايلر ميتواند صرفاً لاگها را در قالب يك پنجره در داخل خود برنامه
به صورت يك ليست به شما نشان دهد (شكل 1).
در ضمن در داخل همين
پنجره ميتوانيد يك الگوي پيشساخته را كه قبلاً توسط خودتان يا ديگران
تنظيم شده مورد استفاده قرار دهيد تا در قسمت بعد كه ميخواهيد رخدادها را
از داخل ليست انتخاب نماييد دچار مشكل نشويد. البته برنامه پروفايلر به
صورت پيشفرض الگوي استاندارد خودش براي نظارت بر عملكرد كاربران و موتور
پايگاه داده را به نام SQL Profilerstandard به شما پيشنهاد ميكند كه
كافي است با قبول كردن آن به زبانه Events برويد. در آنجا طبق الگوي
مذكور، يك سري از رخدادها از داخل ليست سمت چپ به صورت اتوماتيك انتخاب
شده و جهت لاگ شدن در ليست سمت راست قرار ميگيرد، علاوه براي اينكه شما
هم ميتوانيد با استفاده از دو كليدAdd و Remove رخدادهاي موردنظر خودتان
را جهت لاگ شدن به ليست سمت راست، اضافه يا كم كنيد (شكل 2).
 |
|
شكل 3 |
در اينجا فرض بر اين
است كه قصد ما ساختن يك Trace براي كنترل و نظارت بر دستورات SQL در حال
اجرا توسط كاربر مدير سيستم يعني sa ميباشد بنابراين كافيست صرفاً مجموعه
زير گروه TSQL را در ليست سمت راست نگه داريم و بقيه را با كليد Remove به
سر جاي خود يعني ليست سمت چپ برگردانم.
در قسمت بعد بايد
ستونهاي مورد استفاده لاگ را مشخص كنيم. با اين كار پروفايلر اطلاعات
مربوط به لاگهاي توليد شده را به شكل مناسبي كه ما ميخواهيم توليد
ميكند اين انتخاب در زبانه Data Coloumns قابل تنظيم است. به عنوان مثال
ستون TextData متن عبارت SQL در حال اجرا را نشان ميدهد يا اينكه ستون
Application نام برنامه كاربردي كه اين دستور SQL از طرف آن برنامه،
اجرا شده را مشخص مينمايد. بهتر است در اين مرحله كليه ستونهاي پيشفرض
انتخاب شده توسط پروفايلر را قبول كرده و به مرحله آخر يعني فيلتر كردن
اطلاعات برسيم (شكل 3).
 |
|
شكل 4 |
در زبانه فيلتر
(Filter) امكان محدود كردن نمايش اطلاعات لاگ شده (منظور رديفهاي آن
اطلاعات است) به كاربر داده ميشود. به عنوان مثال چون هدف ما صرفاً نمايش
دستورات SQL اجرا شده توسط كاربر sa است، به همين دليل يك فيلتر بر روي
ستون User DataBase تعريف كرده و قسمت like آن را به كلمه sa انتساب
ميدهيم. حتي اگر باز هم قصد محدودتر كردن گزارش را داشته باشيد ميتوانيد
روي ستونهاي ديگر هم فيلتر بگذاريد. مثلاً براي اينكه صرفاً دستورات
DELETE كاربر مذكور به شما نشان داده شود ميتوانيد در همين جا علاوه بر
فيلتر قبل، يك فيلتر جديد بر روي ستون Text Data تعريف كرده و عبارت LIKE
آن را به كلمه DELETE منتسب كنيد (شكل 4).
پس از طي مراحل فوق،
اكنون نوبت به اجراي Trace مذكور ميرسد اينكار از طريق كليك بر روي دكمه
Run انجام ميگيرد. بلافاصله يك پنجره جديد حاوي ستونهايي كه ما در قسمت
Coloumns انتخاب كرده بوديم نمايش داده ميشود. اين ليست بعد از انجام هر
دستور SQL كه شرايط موردنظر ما در قسمت Filter برآورده كند به روز
(Refresh) ميشود و كليه دستورات مذكور را به ترتيب زمان انجام، در درون ليست قرار ميدهد (شكل 5).
 |
|
شكل 5 |








































 نوشته:
نوشته: 
 این وبلاگ به دور از هر گونه حاشیه تنها به مباحث فناوری اطلاعات و ارتباطات می پردازد. برخی مطالب به عنوان نکات قابل توجه از سایتهای دیگر در این وبلاگ درج میشود که حتما از نویسنده اصلی با ذکر منبع تقدیر و تشکر خواهد شد.
این وبلاگ به دور از هر گونه حاشیه تنها به مباحث فناوری اطلاعات و ارتباطات می پردازد. برخی مطالب به عنوان نکات قابل توجه از سایتهای دیگر در این وبلاگ درج میشود که حتما از نویسنده اصلی با ذکر منبع تقدیر و تشکر خواهد شد.